
Trusted #001 - Navigating AI Safety: Exploring the Spectrum of Perspectives on Our Future

This is my first long-form article for Trusted. Please let me know what you think in the comments!
Introduction
Last week, the Future of Life Institute posted an open letter calling for a six-month moratorium on the development of AI models more advanced than GPT-4. The letter was extensively covered in mainstream media publications, with breathless headlines like “Elon Musk and others urge AI pause, citing 'risks to society’”.
As I get started with this newsletter, it doesn’t feel right for me to support AI developments without understanding the concerns that are out there. I’ve spent the last week reading hundreds of pages of discussions in AI safety discussion forums, journal articles, podcasts, and Twitter threads. While my understanding is still pretty limited, I think I’ve gathered enough for some initial thoughts.
This got super long, so I’m going to do this in two parts. In the first part, I’d like to lay out the AI Existential Risk case and the case of those who oppose it, starting by breaking the discussion’s participants into four logical groupings. In the second part next week, I’ll go over some of my principal agreements and disagreements with the arguments that have been presented. (I’m not a philosopher or computer scientist, but I’ve been working in government for 15+ years and know a bit about public/private incentive design and regulatory oversight.)
Understanding the Players
The AI Safety space, just like AI itself, is currently moving exceptionally fast. Normal academic methods of “formal communication via peer-reviewed journal articles” are not keeping up with the speed of development, and many of the players involved are generally distrustful of normal academic methods anyway. Instead, most of the discussion is happening on Twitter, web forums, private Discords, newsletters, take your pick.
As I was going through the debate, I noticed that the discussion groups seemed to break down into four logical groups, so I’ve categorized them as such. (Note: many of the parties involved would disagree with how I’ve categorized things or resist this type of labeling as unhelpful. I get where they’re coming from, but in order to summarize, you end up losing some nuance.)
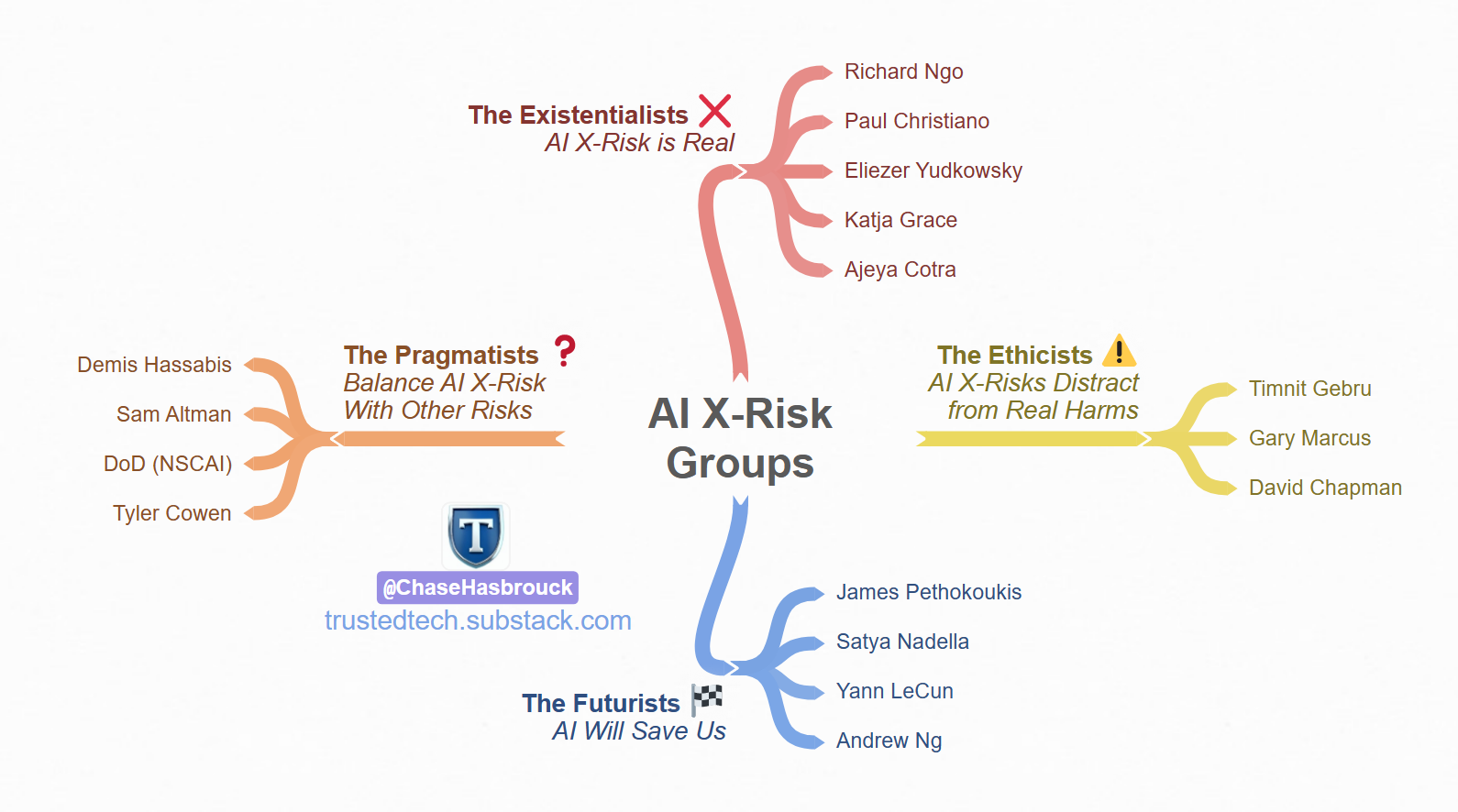
Group 1: The AI Existentialists
This group, which is the most vocal, believes that the development of AI has a significant chance to end the world. (Yes, you read that right.) While they differ strongly on precisely how probable this is, their median prediction is somewhere around a 5-10% chance by 2100.
What is AI Existential Risk? This idea has floated around in SF circles forever, but its growth as an actual theory can largely be traced to the publication of Superintelligence by Nick Bostrom in 2014. In it, he argued that once humans successfully develop human-level AI (frequently called artificial general intelligence or AGI) it is likely to rapidly evolve into a form of “superintelligence” via an "intelligence explosion."
These superintelligences would almost certainly have values that would differ from humans, creating a “misaligned” AI. (In almost all cases, misalignment is accidental; like the story of Midas or the Sorceror’s Apprentice, sometimes the method used to reach a goal ends up causing harm or deviates from intentions. We’ve already seen small real-world examples of this: for example, an AI that was supposed to continuously repeat a series of steps and compare its output to an “answers” file to grade its performance instead learned to delete the “answers” file to maximize its score.) When these types of “oops” mistakes are connected to a superintelligent creation that is powerful enough to learn concepts like deceit and self-preservation, bad things happen, like ending humanity.
This group, like all groups, has internal differences on how strongly they hold this position. The “strong” position, held by Eliezer Yudkowsky, thinks that the timeline from human-level AGI to super AGI to mass extinction will happen very quickly, in the span of months to years, Given this, it is super important that we figure out how to build better alignment measures now, as we won’t get a second chance if we screw up. Many Existentialists agree with this, but think it’s less likely or disagree with some of the particulars of how it will happen.
Examples: Eliezer Yudkowsky, Paul Christiano, Katja Grace, Nate Soares, Ajeya Cotra, and Richard Ngo, though I’m leaving a ton out. This community also overlaps a ton with the effective altruism and rationalist communities, namely people like Scott Alexander and Gwern; their principal Internet hub is LessWrong, which has a ton of info but is also a maze of twisty little rabbit holes, all different. (The Alignment Forum is a less-noisy, curated version of LessWrong.) Cotra and Kelsey Piper have a good newsletter that started last week(!) but is already a great source of info for those less familiar with alignment jargon. Elon Musk also has periodically been involved here, so his name automatically gets attached to everything by media reporting.
This group largely agrees with the letter. Some have signed enthusiastically, some have signed saying “better-than-nothing,” and some (like Yudkowsky) have said it doesn’t go far enough.
Notable quotes:
“If somebody builds a too-powerful AI, under present conditions, I expect that every single member of the human species and all biological life on Earth dies shortly thereafter.” (“Pausing AI Developments Isn't Enough. We Need to Shut it All Down”, Eliezer Yudkowsky, TIME, 2023)
“Powerful AI systems have a good chance of deliberately and irreversibly disempowering humanity. This is a much easier failure mode than killing everyone with destructive physical technologies.” (Where I agree and disagree with Eliezer, Paul Christiano, alignmentforum.org, 2022)
“If you fear that someone will build a machine that will seize control of the world and annihilate humanity, then one kind of response is to try to build further machines that will seize control of the world even earlier without destroying it, forestalling the ruinous machine’s conquest. An alternative or complementary kind of response is to try to avert such machines being built at all, at least while the degree of their apocalyptic tendencies is ambiguous.” (“Let’s think about slowing down AI”, Katja Grace, alignmentforum.org, 2022)
Group 2: The Ethicists
This group has differing views on existential risk, but they’re less interested in that; and more interested in how AI’s are doing bad things right now.
They differ on their primary concern. Some think that AI’s will spread disinformation at scale. Some think that AI adoption will accelerate inequality and labor strife by getting rid of jobs and disrupting the economy. Some think they will cause mass political instability by reshaping the world’s power structure. Some think they are just way too unreliable a product to be rolled out worldwide, and are afraid people will start hooking up mission-critical systems to them.
Like the Existentialists, some of this group signed the open letter as a partial solution, some opposed it.
Examples: Gary Marcus, Timnit Gebru, David Chapman
Notable Quotes:
I am not worried, immediately, about “AGI risk” (the risk of superintelligent machines beyond our control), in the near term I am worried about what I will call “MAI risk”—Mediocre AI that is unreliable (a la Bing and GPT-4) but widely deployed—both in terms of the sheer number of people using it, and in terms of the access that the software has to the world. (“AI risk ≠ AGI risk,” Gary Marcus, garymarcus.substack.com, 2023)
The harms from so-called AI are real and present and follow from the acts of people and corporations deploying automated systems. Regulatory efforts should focus on transparency, accountability and preventing exploitative labor practices. (“Statement from the listed authors of Stochastic Parrots on the “AI pause” letter”, Timnit Gebru et al., dair-institute.org, 2023)
“The safety community’s apocalyptic AI scenarios commonly end the world with nuclear or biological weapons…I think most lay people would find political incoherence scenarios far more plausible than many contemplated in the AI safety field. “Malevolent AI takes over the world and turns everyone into paperclips” sounds like a kids’ cartoon; “American politics gets so insane and hostile that we have a civil war, Russia and China take sides, and eventually it goes nuclear” sounds quite realistic.” (“What an AI apocalypse may look like,” David Chapman, betterwithout.ai, 2023)
Group 3: The Pragmatists
This group largely agrees with the existentialists that AI’s present a risk, but has significant objections to it, or thinks some other issue is more important. This group has a few main subgroups.
The first subgroup are the “incrementalists”, who think that the only way to make safe AGI is to 1) build increasingly advanced models and learn from them, and 2) do it quickly, before unsafe actors have a chance to build their own models. The major AI labs generally take this position; OpenAI’s “Planning for AGI and Beyond” blog post from February lays this out well. Anthropic’s position is similar, though they are closer to Group 1. (I can’t find a specific statement on this from DeepMind, but they are similar also from what I’ve observed.)
The second subgroup are the “strategists,” who see AI as so critical to either the economy or national security that any type of delay is riskier than the alternative. The best summary of this perspective is probably the U.S. National Security Commission on AI’s (NSCAI) report from 2021, who is broken into two parts: Defending America and Winning the AI Competition. (The closest it gets to talking about safety is making sure the systems work correctly so that they can be counted on.)
This group is opposed to the open letter. The incrementalists think that while cutting off AI progress may make sense in the future, it’s way too soon to do that now. The strategists see AI as a competition or arms race and feel that any delay is obviously counterproductive. Some of this group also has specific criticisms, noting that even if a delay was the right thing to do, there’s no realistic option on how to enforce that delay right now.
Examples: Sam Altman/Greg Brockman/Ilya Sutskever, OpenAI; Demis Hassabis, DeepMind; Tyler Cowen, economist
Notable Quotes:
“things we need for a good AGI future: 1) the technical ability to align a superintelligence 2) sufficient coordination among most of the leading AGI efforts 3) an effective global regulatory framework including democratic governance” (Tweet, Sam Altman, Twitter, 2023)
“The ability of a machine to perceive, evaluate, and act more quickly and accurately than a human represents a competitive advantage in any field—civilian or military. AI technologies will be a source of enormous power for the companies and countries that harness them.” (NSCAI Final Report Executive Summary, U.S. National Security Commission on AI, nscai.gov, 2021)
Group 4: The Futurists
Finally, the Futurists. This group thinks the existentialists are crazy. The AI train is about to leave the station for Utopia, and it’s time to get on board.
There’s a mix of personalities in here, so nothing I would call an actual sub-group. there’s some techno-optimists in here who think AGI is going to be strongly positive for humanity, some businessmen who see AI as an emerging market for their company, and some researchers who just want to build cool stuff and think risk talk is ridiculous and wildly premature. Naturally, this group is directly opposed to the Existentialists, and they spend a lot of time sniping at each other on Twitter. They all directly oppose the “open letter.”
Examples: Yann LeCun, Meta; Satya Nadella, Microsoft; Joscha Bach/Andrew Ng, researchers; James Pethokoukis, futurist
Notable Quotes:
“The *only* reason people are hyperventilating about AI risk is the myth of the "hard take-off": the idea that the minute you turn on a super-intelligent system, humanity is doomed. This is preposterously stupid and based on a *complete* misunderstanding of how everything works.” (Tweet, Yann LeCun, Twitter, 2023)
“The call for a 6 month moratorium on making AI progress beyond GPT-4 is a terrible idea. I'm seeing many new applications in education, healthcare, food, ... that'll help many people. Improving GPT-4 will help. Lets balance the huge value AI is creating vs. realistic risks.” (Tweet, Andrew Ng, Twitter, 2023)
“I fear that embedded within the Pause is the better-safe-than-sorry Precautionary Principle that will one day push for a permanent pause with humanity well short of artificial general intelligence. That, whether for concerns economic or existential, would deprive humanity of a potentially powerful tool for human flourishing.” (“No to the AI Pause,” James Pethokoukis, fasterplease.substack.com, 2023)
Conclusion
So where do I land in all this? As a natural consensus builder, I’m taking the boring, politically-correct approach of “they’ve all got some good points.”
I agree with the Existentialists that AI alignment is absolutely something that needs to be taken seriously, and their argument is plausible, but I think the risks are probably closer to 1 in 1000 than 1 in 10. I also can’t help but think that Eliezer Yudkowsky’s predictions sound very much like Paul Ehrlich’s predictions.
I agree with the Ethicists that there are real harms from AI that are happening now and need to be addressed, but would like to see some productive discussions on how to best resolve those harms that also discuss economic incentives.
I agree with the Pragmatists that learning as we go is probably the best approach to doing alignment well, and that a moratorium now is impractical, but I’m not sure committing to an “arms race” framing is helpful. I also think China is practically farther behind on AI, and there’s been too many specious comparisons like “number of citations in AI journals.”
I agree with the Futurists that AI is super-cool, but I don’t think the impact is going to be as transformative as they expect. I also think there’s a lot of technological improvements to neural networks that need to happen.
Thanks for reading. Please subscribe if you like this, share with others who might be interested, and let me know your thoughts in the comments!
Standard disclaimer: All views presented are those of the author and do not represent the views of the U.S. government or any of its components.
I've been following this stuff for some time now and I think this is an interesting and useful piece of work. It will be interesting to see how this evolves.
One further comment. It seems to me that belief in AI x-risk exists mostly along a Silicon Valley to London/Oxford axis. That suggests to me that x-risk has a cultural aspect to it. Here's a post where I wonder why the Japanese don't seem worried: https://new-savanna.blogspot.com/2022/05/whos-losing-sleep-at-prospect-of-ais.html
More generally, I've been posting on the subject for awhile. This is a link to my posts: https://new-savanna.blogspot.com/search/label/Rogue-AI
Appreciate the graphic and categorization.
Just wanted to share that it may not even be the big labs creating the risk now that so much is public.
AutoGPT seems to be a step along the paperclip scenario.
https://github.com/Torantulino/Auto-GPT